



SMACK: Short Meetings on Astro Computing Knowledge
Talks given in live demostration format on software and tools for astronomical research. Supported by EuroCC. Supplementary materials at gitlab.

Abstract
Short Meetings on Astro Computing Knowledge (SMACK) are a series of talks, or more appropriately 'live demonstrations', presented in the Instituto de Astrofísica de Canarias (IAC), targeting graduate students and researchers. The main aim of the talks is to demonstrate the use and benefits of basic software tools that are commonly required for astronomical research. These talks will be showcasted at IAC Talks and recorded for easy future reference by the community.
The 1st SMACK is a brief introduction to the linux shell and the basic tools that come with it. We'll assume no previous knowledge and include a brief history of the POSIX standard.
Abstract
The shell (or command-line) is the most commonly used (for advanced operations) interface to Unix-like operating systems.
In this session we'll introduce some of the most commonly used command-line/shell features and how they may be used in a hypothetical research project, using real astronomical data sets.
The session plan (with a listing of used commands and short explanation) is available here: https://gitlab.com/makhlaghi/smack-talks-iac/-/blob/master/smack-2-shell.md
https://rediris.zoom.us/j/98301657954
Abstract
Gnuastro is an official GNU package that is currently maintained at the IAC. It is a large collection of programs to enable easy, robust, fast and efficient data analysis directly on the command-line. For example it can perform arithmetic operations on image pixels or table columns/rows without having to write programs, visualize FITS images as JPG or PDF, convolve an image with a given kernel or matching of kernels, perform cosmological calculations, crop parts of large images (possibly in multiple files), manipulate FITS extensions and keywords, and perform statistical operations. In addition, it contains programs to make catalogs from detection maps, add noise, make mock profiles with a variety of radial functions using monte-carlo integration for their centers, match catalogs, and detect objects in an image among many other operations. Gnuastro is written to comply fully with the GNU coding standards and integrates well with all Unix-like operating systems. This enables astronomers to expect a fully familiar experience in the building, installing and command-line user interaction that they have seen in all the other GNU software that they use (core components in many Unix-like/POSIX operating systems). In this SMACK, we will introduce Gnuastro and demonstrate a selection of its commonly used features. Relevant links are as follows. Lecture-notes: in https://gitlab.com/makhlaghi/smack-talks-iac/-/blob/master/smack-3-gnuastro.md, Gnuastro's main webpage: https://www.gnu.org/s/gnuastro, Gnuastro documentation: https://www.gnu.org/s/gnuastro/manual, Gnuastro tutorials: https://www.gnu.org/s/gnuastro/manual/html_node/Tutorials.html
Zoom link https://rediris.zoom.us/j/94454701469
Abstract
In the previous SMACKs, basic operations on the command-line were reviewed in interactive mode: where you enter one command, wait for it to finish and enter the next command. The shell's interactive mode is good for small/fast tests, but is not scalable. For example when you know the commands and parameters work and want to apply them to hundreds/thousands of targets. Shell scripts are simply plain-text files that store all the various commands that you want to be executed in sequence. They are designed precisely for the easier management of operations that are more complex than a simple command. In fact many of the commands in the Unix-like operating systems are actually shell scripts! Here will review some basic intricacies with designing robust shell scripts and avoiding common pitfalls. Also, since shell scripts are simple plain-text files, we will also do a short review of simple plain-text editors like GNU Nano and more advanced editors like Vim and GNU Emacs. Advanced editors have many useful features to simplify programming in many languages (including shell programming) and don't need complex graphic environments and can be run in the raw command-line (a major advantage when scaling your project up to supercomputers that don't have a graphic environment). For newcomers to data-intensive astronomical research, we encourage you to select an advanced editor, and master it early to greatly simply your research (in any language).

Abstract
Git is probably the most widely used Version Control System (software tools that help record changes to files (computer code, text files, etc.) by keeping track of modifications done through time). It can be used for any type of text files, though it is specially useful for programming code and it makes managing your projects, files, and changes made to them much easier and more intuitive.
But it is a big and complex system and people new to it can have a hard time mastering it. In this talk I will introduce the git version control system to people that have never used it before, so I will go over its basic concepts and functionalities from the ground-up. I will cover the most common commands, needed to use Git for your own individual projects. Once you properly understand how to use it on your own, it is much easier to understand how to collaborate with others (for example using GitHub), which will be covered in a follow-up talk: "Intermediate Git".

Abstract
Following up on our previous "Git version control system basics" seminar (https://bit.ly/35CCX7k), the focus of this talk will be to learn the features of Git that will allow us to collaborate with other colleagues. For this, the main concepts needed are branch merging (including merges with conflicts), remote repositories and hosted repositories (GitHub, GitLab, Bitbucket, etc.).
Thanks to the distributed structure of Git, collaboration with colleagues can become very efficient (allowing for many different workflows) and it avoids the single point of failure of centralized version control systems, but its complexity also goes up. Properly understanding the concept of remote repositories makes collaboration with Git straightforward.
Other Git features and tools that are not essential, but that will make Git usage much more effective and powerful (like stash, rebase, pull requests, etc.) will be left for a planned "Advanced Git" follow-up talk.
Abstract
This talk will give an overview of the resources for scientific computing at the IAC. The network, los burros, and LaPalma will be described, together with the basics for using them and practical examples.
Speakers: Ana Esteban, Carlos Allende, Isaac Alonso and Juan Carlos Trelles (IAC)
Abstract
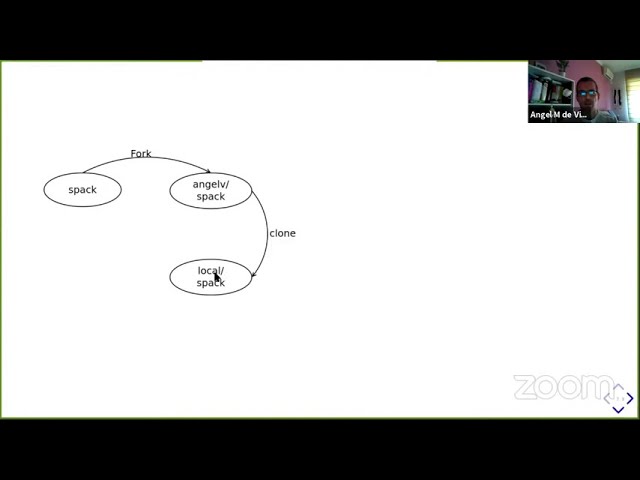
In two previous talks we covered the basics of Git (http://iactalks.iac.es/talks/view/1426) and some intermediate concepts (http://iactalks.iac.es/talks/view/1428). In this one we will focus on more advanced features that can make your Git experience much more productive and efficient.
First we will focus on a very common collaboration "procedure", which we didn't have time to cover in any detail in the "Intermediate Git" talk, namely "Pull requests".
Next, since most of your work with Git will be on local repositories, we will see some more advanced commands and features, such as pull requests, rebase, reset, hunks, reflog, stash and blame.
While this series on Git doesn't cover everything there is to Git, it does cover almost all you'll need to become a regular Git user.
Abstract
In the last decade, Python went from being a moderated-used programming language in the astronomical community to the de-facto standard in Astronomy. Its recent growth has been spectacular, thanks to the coordination and work of the community to create astropy, the core astronomy library, as well as other base libraries like numpy and matplotlib. However, the current scientific/astronomical ecosystem for Python is huge and sparse, introducing many types of objects and methods, often confusing at the beginning.
In this SMACK talk I will describe the current status of the Python ecosystem for astronomy and introduce the most import elements of the core libraries, numpy and astropy, showing with practical examples how they provide new impressive capabilities to deal with data, catalogs, coordinates and much more, making life easier for astrophysicists.
Abstract
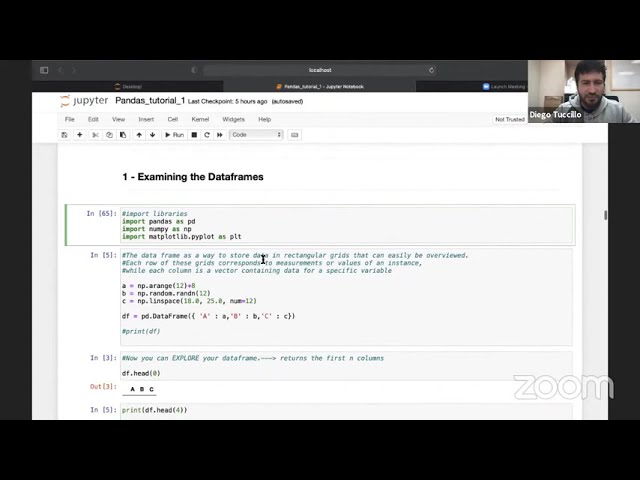
Pandas is an open source Python package that is widely used for data analysis. It is a powerful ally for data munging/wrangling and databases manipulation/visualisation, and a must-have tool for Data Scientists. In this seminar we will have a general overview on its functionality and we will run over some of the reasons of its large success in the Data Science community.
Abstract
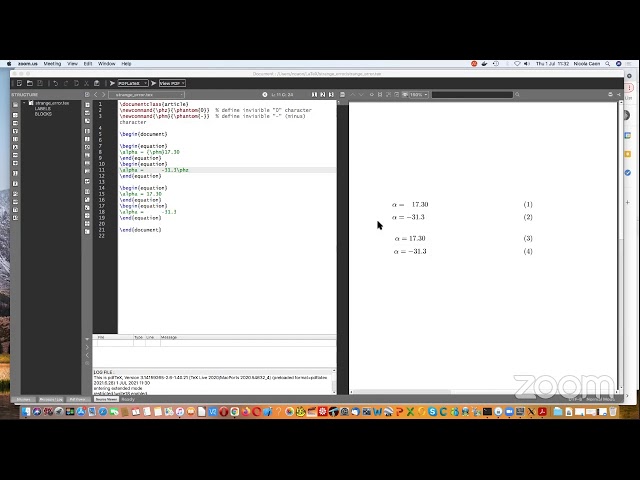
This talk will present an overview of what Latex is, discuss when to use it and when not, show installing and editing options, introduce classes and packages, and give some usage recommendations and troubleshooting tips.
Abstract
We will introduce several ways in which trivially embarrassingly parallel tasks can be run in laptops and desktops. We will introduce command-line tools such as GNU parallel and Kiko. We will then focus on simple techniques for optimisation of scientific computations in python. We will cover parallel computing with multiprocessing, acceleration of functions via numba, and GPU computing with cupy. The goal is to provide an easy roadmap for python code optimisation methods that can applied on already existing code, without writing a single line of C or FORTRAN.

CEFCA
Abstract
Containers are portable environments that package up code and all its dependencies so that an application can run quickly and reliably from one computing environment to another. Most people are probably familiar with full virtualization environments (such as VirtualBox), so in this talk we will explain the main differences between full virtualization and containers (sometimes called light-weight virtualization), and when to use each.
At the same time, not all container technologies have the same goals and/or approaches. Docker is the most mature container offering, but it is geared mainly towards micro-services. Singularity is a newer contender, with an emphasis on mobility of compute for scientific computing. We will introduce both softwares, showing how to create and use containers with each of them, while discussing real-life examples of their use.
The lecture notes can be found here:
https://gitlab.com/makhlaghi/smack-talks-iac/-/blob/master/smack-13-docker.md
CEFCA
Abstract
Did you ever want to re-run your project from the beginning, but run into trouble because you forgot one step? Do you want to run just one part of your project and ignore the rest? Do you want to run it in parallel with many different inputs using all the cores of your computer? Do you want to design a modular project, with re-usable parts, avoiding long files hard to debug?
Make is a well-tested solution to all these problems. It is independent of the programming language you use. Instead of having a long code hard to debug, you can connect its components making a chain. Make will allow you to automate your project and retain control of how its parts are integrated. This SMACK seminar will give an overview of this powerful tool.
Gitlab link: https://gitlab.com/makhlaghi/smack-talks-iac/-/tree/master/

Abstract
PyCOMPSs is a task-based programming in Python that enables simple sequential codes to be executed in parallel in distributed computing platforms. It is based on the addition of python decorators in the functions of the code to indicate those that can be executed in parallel between them. The runtime takes care of the different parallelization and resource management actions, as well as of the ditribution of the data in the different nodes of the computing infrastructure. It is installed in multiple supercomputers of the RES, like MareNostrum 4 and now LaPalma. The talk will present an overview of PyCOMPSs, two demos with simple examples and a hands-on in LaPalma on how we can parallelize EMCEE workloads.
Slides and Examples: https://gitlab.com/makhlaghi/smack-talks-iac
CEFCA
Abstract
LaTeX is a professional typesetting system to create a ready-to-print or publish (usually PDF!) document (usually papers!). LaTeX is the format used by arXiv, and many journals, when you want to submit your scientific papers. With LaTeX, you "program" the final document: text, figures, tables, bibliography and etc, through a plain-text (source) file. When you run LaTeX on your source, it will parse your LaTeX source and find the best way to blend everything in a nice and professionally design PDF document. Therefore LaTeX allows you to focus on the actual content of your text, tables, plots, and not have to worry about the final design (the "style" file provided by the journal will do all of this for you automatically). This is in contrast to "What-You-See-Is-What-You-Get" (or WYSIWYG) editors, like Microsoft Word or LibreOffice Writer, which force you to worry about style in the middle of content writing (which is very frustrating). Since the source of a LaTeX document is plain-text, you can use version-control systems like Git to keep track of your changes and updates (Git was introduced in SMACK 5, SMACK 6 and SMACK 8). This feature of LaTeX allows easy collaboration with your co-authors, and is the basis of systems like Overleaf. Previously (in SMACK 11), some advanced tips and tricks were given on the usage of LaTeX. This SMACK session is aimed to complement that with a hands-on introduction for those who are just starting to use LaTeX. It is followed by SMACK 17 on other basic features that are necessary to get comfortable with LaTeX.
Lecture notes: https://gitlab.com/makhlaghi/smack-talks-iac/-/blob/master/smack-16-latex.md
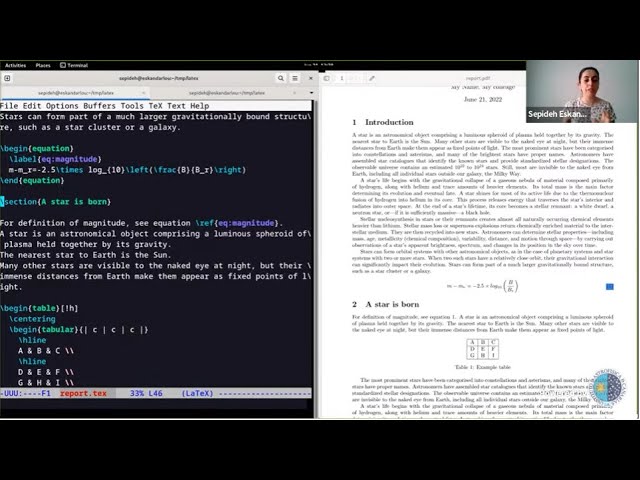
Abstract
In the 16th SMACK, the very basics of LaTeX were introduced; showing how to make a basic document from scratch, set the printable size, inserting images and tables and etc. In this session, we will go into more advanced features that are also commonly helpful when preparing a professional document (while letting you focus on your exciting scientific discovery, and not have to worry about the style of the output). These features include automatically referencing different parts of your document using labels (this allows you to easily shuffle figures, sections or tables), making all references to various parts of your text click-able (greatly simplifying things for your readers), using Macros (to avoid repetition or importing your analysis results automatically), adding bibliography, keeping your LaTeX source, and your top directory clean, and finally using Make to easily automate the production of your document.
Lecture notes: https://gitlab.com/makhlaghi/smack-talks-iac/-/blob/master/smack-17-latex-b.md
Abstract
The first part of this talk will present an overview of the tool "module" and its main commands and flags. "module" provides the dynamic modification of the user’s environment for supporting multiple versions of an application or a library without any conflict. In the second part, we’ll first explain what Python virtual environments are, and describe three actual cases in which they are used. We’ll then illustrate a practical example to install a Python virtual environment, and duplicate it on a different platform.

Abstract
In a time when we deal with extremely large images (be it from computer
simulations or from extremely powerful telescopes), visualizing them can
become a challenge. If we use a regular monitor, we have two options:
1) fit the image to our monitor resolution, which involves interpolation
and thus losing information and the ability to see small image details.
2) zooming in on small parts of the image to view them at full
resolution, which involves losing context and the global view of the
full image.
To alleviate these problems, display walls of hundreds of Megapixels can
be built, which allow us to visualize in full resolution small details
of the images while retaining in view a larger image context. For
example, one of the world's highest resolution tiled-displays is
Stallion (https://www.tacc.utexas.edu/vislab/stallion, at the TACC in
Texas, USA), with an impressive resolution of 597 Megapixels (an earlier
version of the system can be seen being used at
https://tinyurl.com/mt7atad9).
At the IAC we have built a more modest display wall (133 Megapixels),
which you probably have already seen in action in one of our recent
press releases (https://tinyurl.com/4bwtxvec). In this talk I will
introduce this new visualization facility (which any IAC researcher can
use) and discuss on some design issues, possible current and future
uses, limitations, etc.

Abstract
We divide this talk into two parts. In the first part, we will introduce the numerical codes we use, mainly in solar physics, to infer information about the solar atmosphere from spectro-polarimetric observations. In particular, we will present a new version that was recently developed (see Ruiz Cobo et al., 2022). In the second part of the talk, we will learn how we opted to bring the code to the public through online tutorials, and we will show where to find them (see the link below). Also, we will explain why we believe this new approach could be interesting for other research areas and give some tips in case someone is interested in trying the method.

Abstract
Slurm Workload Manager (formerly known as Simple Linux Utility for Resource Management (SLURM), or simply Slurm, is a free and open-source job scheduler for Linux and Unix-like kernels, used by many of the world's supercomputers and computer clusters. While Slurm has been used at the IAC in the LaPalma supercomputer and deimos/diva for a long time, we are now starting to also use it in public "burros" (and project burros that request it), in order to ensure a more efficient and balanced use of these powerful (but shared amongst many users) machines. While using Slurm is quite easy, we are aware that it involves some changes for users. To help you understand how Slurm works and how to best use it, in this talk I will focus on: why we need queues; an introduction to Slurm usage; Slurm configuration in LaPalma/diva/burros; use cases (including interactive jobs); ensuring a fair usage amongst users and an efficient use of the machines; etc. [If you are already a Slurm user and have specific questions/comments, you can post them in the #computing/slurm stream in IAC-Zulip (https://iac-es.zulipchat.com) and I'll try to cover them during the talk]
Abstract
Gone are the days when we used workstations as our main day to day computer. Backing-up your data has always been important, but the risks were much fewer then. Today, when most of us use a laptop as our main computer, the risks are much higher: added to human error, disk failures, etc. we have to consider that losing, dropping or getting your laptop stolen is a real possibility, which brings the added risk of getting your sensitive data accessed by prying eyes. In this talk I will share my overall backup plan. While my setting is likely more complicated than that of most of you, hopefully you can mix & match the strategies and tools that I use (mainly Borg, but also Timeshift, Clonezilla, Syncthing, gocryptfs, ...) to suit your needs. While a complete and thorough backup plan might take some time to prepare and execute, you shouldn't postpone it. Something is better than nothing!, and you can start with something very simple, which can be very easy to implement, and can be improved over time.
Upcoming talks
- The Emergence of Dwarf Galaxies, Star Clusters and Something In-betweenDr. Justin ReadThursday June 26, 2025 - 10:30 GMT+1 (Aula)
- Estado actual del Centro de Sistemas Ópticos Avanzados (CSOA)Friday June 27, 2025 - 10:30 GMT+1 (Aula)
Recent Colloquia



Recent Talks


