Found 30 talks width keyword Big data

Abstract
First in the lecture series on deep learning for astronomy. This series is designed to provide clear and accessible introductions to key deep learning techniques, with examples of their applications to astronomical data and research. In the first session we shall provide a brief history of deep learning and introduce the intuition and basic math behind NNs, together with examples related to data fitting with basic NN (slides and code provided in .https://github.com/cwestend/IACDEEP_introNN/)

Abstract
Galaxies and the dark matter halos in which they reside are intrinsically connected. That relationship holds information about key processes in galaxy and structure formation. In this talk, I will consider how the galaxy-halo connection depends on position within the cosmic web - the familiar decomposition of large-scale structure in filaments, knots and voids. Simulations demonstrate the various ways in which the cosmic web modulates the growth and dynamics of halos. The extent to which the cosmic web impacts on galaxies is more difficult to establish. For example, galaxies might be sensitive only to the evolution of the host halo, in which case any effect of the cosmic web on galaxies is secondary, and can be inferred from the halo's history. There is evidence, however - from simulations and observations - that the cosmic web also impacts on the evolution of galaxies via the effect it has on the broader gas ecosystem in which they are embedded, as well as through "pre-processing" effects on group scale. So, how should we think of the cosmic web in its role as a transformative agent of galaxies? And what physical processes can we convincingly constrain from observations and simulations? In this talk I highlight recent work that addresses these questions.
Abstract
A key problem that we are facing in cosmology nowadays is that we cannot make accurate predictions with our current theoretical models. We have all of the pieces of the standard model but it doesn't have an analytical solution. The only way to have accurate predictions is to run a cosmological simulation. Then, why not use these simulations as the theory model? Well, for one main reason, if we want to explore the full parameter space comprised in the standard model, we need thousands of such simulations, and they are terribly computationally expensive. We wouldn't be able to do it in years! In this talk, I will tell you how in the last few years we have come up with a way to circumvent this problem.
CEFCA
Abstract
Did you ever want to re-run your project from the beginning, but run into trouble because you forgot one step? Do you want to run just one part of your project and ignore the rest? Do you want to run it in parallel with many different inputs using all the cores of your computer? Do you want to design a modular project, with re-usable parts, avoiding long files hard to debug?
Make is a well-tested solution to all these problems. It is independent of the programming language you use. Instead of having a long code hard to debug, you can connect its components making a chain. Make will allow you to automate your project and retain control of how its parts are integrated. This SMACK seminar will give an overview of this powerful tool.
Gitlab link: https://gitlab.com/makhlaghi/smack-talks-iac/-/tree/master/

Abstract
The field of Galactic archaeology has been very active in recent years, with a major influx of data from the Gaia satellite and large spectroscopic surveys. The major science questions in the field include Galactic structure and dynamics, the accretion history of the Milky Way, chemical tagging, and age-abundance relations. I will give an overview of GALAH as a large spectroscopic survey, and describe how it is complementary to other ongoing and future survey projects. I will also discuss recent science highlights from the GALAH team and compelling questions for future work.
Abstract
We will introduce several ways in which trivially embarrassingly parallel tasks can be run in laptops and desktops. We will introduce command-line tools such as GNU parallel and Kiko. We will then focus on simple techniques for optimisation of scientific computations in python. We will cover parallel computing with multiprocessing, acceleration of functions via numba, and GPU computing with cupy. The goal is to provide an easy roadmap for python code optimisation methods that can applied on already existing code, without writing a single line of C or FORTRAN.

Abstract
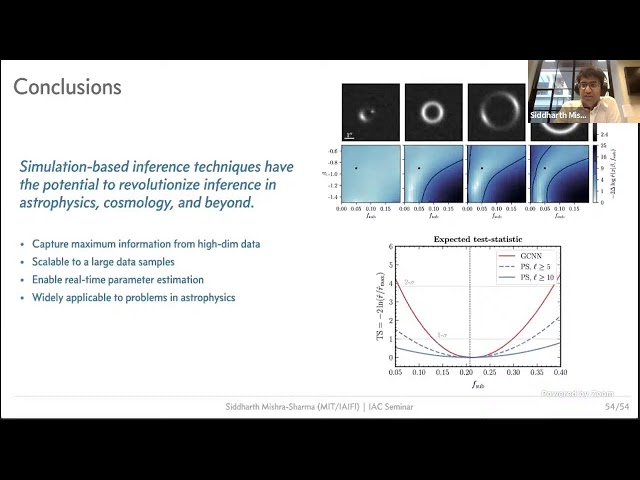
Abstract
The next decade will see a deluge of new cosmological data that will enable us to accurately map out the distribution of matter in the local Universe, image billions of stars and galaxies to unprecedented precision, and create high-resolution maps of the Milky Way. Signatures of new physics as well as astrophysical processes of interest may be hiding in these observations, offering significant discovery potential. At the same time, the complexity of astrophysical data provides significant challenges to carrying out these searches using conventional methods. I will describe how overcoming these issues will require a qualitative shift in how we approach modeling and inference in cosmology, bringing together several recent advances in machine learning and simulation-based (or likelihood-free) inference. I will ground the talk through examples of proposed analyses that use machine learning-enabled simulation-based inference with an aim to uncover the identity of dark matter, while at the same time emphasizing the generality of these techniques to a broad range of problems in astrophysics, cosmology, and beyond.
https://rediris.zoom.us/j/83193959785?pwd=TExXSDJ6UDg5a24yWDM1TnlOWkNTZz09
Meeting ID: 831 9395 9785
Passcode: 343950O
YouTube: https://youtu.be/1Nkzn-cGaIo
Abstract
Galaxy morphologies are one of the key diagnostics of galaxy evolutionary tracks, but visual classifications are extremely time-consuming. The sheer size of Big Data surveys, containing millions of galaxies, make this approach completely impractical. Deep Learning (DL) algorithms, where no image pre-processing is required, have already come to the rescue for image analysis of large data surveys. In this seminar, I will present the largest multi-band catalog of automated galaxy morphologies to date containing morphological classifications of ∼27 million galaxies from the Dark Energy Survey. The classification separates: (a) early-type galaxies (ETGs) from late-types (LTGs); and (b) face-on galaxies from edge-on. These classifications have been obtained using a supervised DL algorithm. Our Convolutional Neural Networks (CNNs) are trained on a small subset of DES objects with previously known classifications, but hese typically have mr < 17.7 mag. We overcome the lack ofa training sample by modeling fainter objects up to mr < 21.5 mag, i.e., by simulating what thebrighter objects with well-determined classifications would look like if they were at higher redshifts.The CNNs reach a 97% accuracy to mr < 21.5 on their training sets, suggesting that they are ableto recover features more accurately than the human eye. We obtain secure classifications for 87%and 73% of the catalog for the ETG vs. LTG and edge-on vs. face-on models, respectively.
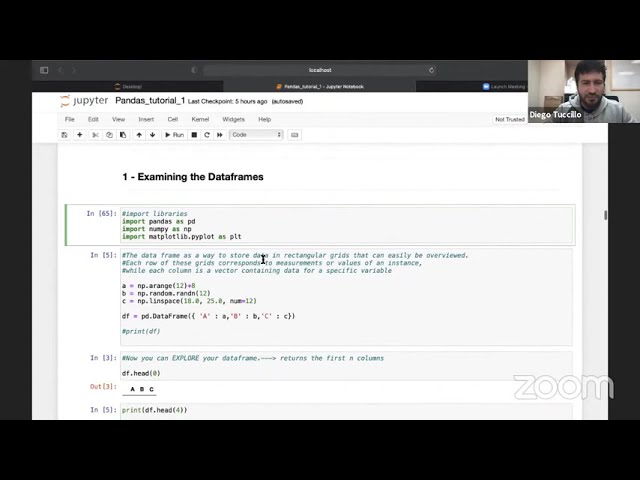
Abstract
Pandas is an open source Python package that is widely used for data analysis. It is a powerful ally for data munging/wrangling and databases manipulation/visualisation, and a must-have tool for Data Scientists. In this seminar we will have a general overview on its functionality and we will run over some of the reasons of its large success in the Data Science community.
« Newer 1 | 2 | 3 Older » Last >>
Upcoming talks
- Quantum Simulators for the Cosmos: From Confining Strings to the Early UniverseDr. Enrique Rico OrtegaThursday December 4, 2025 - 10:30 GMT (GTC)
- Colloquium by Junbo ZhangDr. Junbo ZhangThursday December 11, 2025 - 10:30 GMT (Aula)
Recent Colloquia



Recent Talks